硬件加速
妙幕(SmartSub)支持多种硬件加速方式,可以显著提高语音识别和字幕生成的速度。本章节详细介绍如何配置和使用硬件加速功能,充分发挥您设备的性能潜力。
支持的硬件加速类型
妙幕目前支持两种主要的硬件加速方式:
- NVIDIA CUDA:适用于搭载 NVIDIA 显卡的 Windows 和 Linux 系统
- Apple Core ML:适用于搭载 Apple Silicon(M系列)芯片的 Mac 设备
NVIDIA CUDA 加速
系统要求
要使用 CUDA 加速,您的系统需要满足以下条件:
- 搭载支持 CUDA 的 NVIDIA 显卡
- 安装与显卡兼容的 CUDA Toolkit
- 使用支持 CUDA 的妙幕版本
支持的 CUDA 版本
妙幕提供了支持不同 CUDA 版本的安装包:
| 安装包 | 支持的 CUDA 版本 | 适用场景 |
|---|---|---|
| windows-x64_cuda11.8.0 | CUDA >= 11.8.0 < 12.0.0 | 较老的显卡或系统 |
| windows-x64_cuda12.2.0 | CUDA >= 12.2.0 | 较新的显卡和系统 |
| windows-x64_cuda12.4.0 | CUDA >= 12.4.0 | 最新的显卡和系统 |
- 通用版本(generic):适用于大多数NVIDIA显卡
- 优化版本(optimized):针对特定显卡系列优化,提供更好的兼容性和性能
CUDA Toolkit 安装
- 访问 NVIDIA CUDA 下载页面
- 选择您的操作系统、架构和系统版本
- 下载并安装 CUDA Toolkit
- 重启计算机完成安装
CUDA Toolkit 版本应与您的显卡驱动兼容。通常,更新的 CUDA 版本会要求更新的显卡驱动。
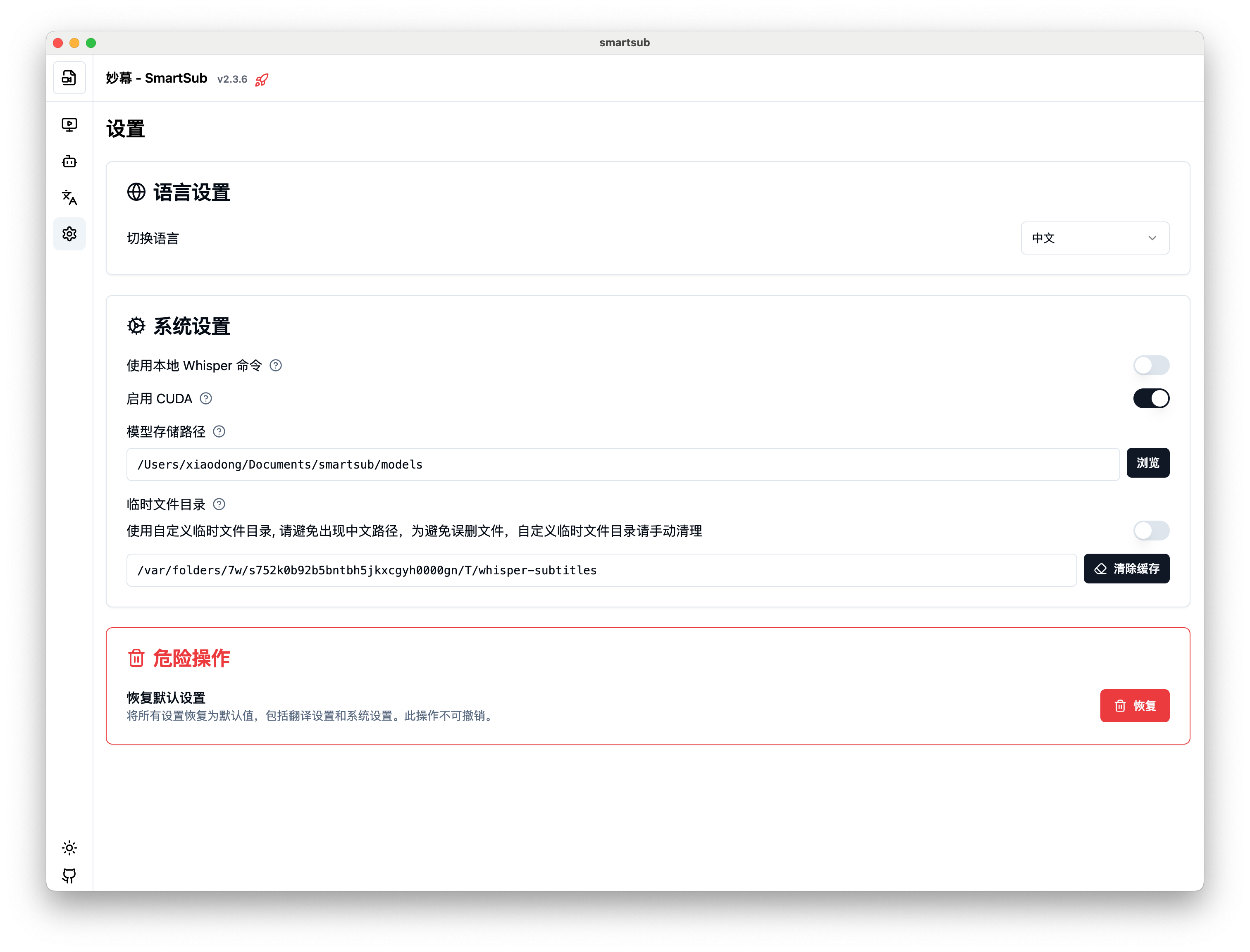
在妙幕中启用 CUDA 加速
- 启动妙幕应用
- 进入"设置" > "系统设置"卡片栏
- 在"启用 CUDA"选项中选择 "CUDA"
验证 CUDA 是否正常工作
- 启动一个字幕生成任务
- 查看处理日志,应该会显示使用 CUDA 进行处理
- 比较使用 CUDA 和不使用 CUDA 的处理速度,应该能看到明显提升
CUDA 加速性能优化
-
选择合适的模型:
- 较大的模型(如 medium 或 large)能更好地利用 CUDA 加速
- 较小的模型(如 tiny 或 base)在 CUDA 加速下提升可能不那么明显
-
显存管理:
- 更大的模型需要更多显存
- 如果显存不足,可能会导致性能下降或错误
- 通常 4GB 显存可以良好运行 small 模型,8GB 以上显存可以运行 large 模型
-
并行任务调整:
- 在使用 CUDA 时,减少并行任务数可能提供更好性能
- 单个强大的 CUDA 任务通常比多个 CPU 任务更高效
Apple Core ML 加速
系统要求
要使用 Core ML 加速,您的系统需要满足以下条件:
- 搭载 Apple Silicon(M1/M2/M3系列)芯片的 Mac 设备
- macOS 12 (Monterey) 或更新版本
- 使用针对 arm64 架构编译的妙幕版本 (mac-arm64)
自动启用
在支持的 Mac 设备上,妙幕会自动检测 Apple Silicon 芯片并启用 Core ML 加速,无需手动配置。
特殊模型要求
对于 Core ML 加速,非量化模型(非 q5 或 q8 系列)需要下载对应的 encoder.mlmodelc 文件:
-
从模型源下载对应的
encoder.mlmodelc文件: -
将下载的文件放置在模型同一目录中
q5 或 q8 系列的量化模型(如 small.q5_0)不需要额外的 encoder.mlmodelc 文件即可使用 Core ML 加速。
验证 Core ML 是否正常工作
- 启动妙幕应用
- 在"设置" > "通用"中,"音频设备"应自动显示为 "Core ML"
- 启动一个字幕生成任务
- 查看处理日志,应该会显示使用 Core ML 进行处理
Core ML 性能优化
-
更新系统:
- 保持 macOS 系统更新到最新版本以获取最佳 Core ML 性能
- 更新的系统版本通常包含 Neural Engine 性能优化
-
电源管理:
- 在处理大量任务时,将 Mac 连接到电源
- 关闭不必要的后台应用,减少系统负载
-
模型选择:
- 在 Apple Silicon 上,medium 模型通常能提供良好的性能和准确度平衡
- 量化模型(如 medium.q8_0)在保持大部分准确度的同时,可以减少内存占用
性能对比
下面是不同硬件加速方式处理一个10分钟视频的大致性能对比(使用 medium 模型):
| 处理方式 | 处理时间 | 相对速度 | 内存占用 |
|---|---|---|---|
| CPU (8核) | 15-25分钟 | 1x | 中等 |
| NVIDIA GTX 1660 | 5-8分钟 | 3x | 高 |
| NVIDIA RTX 3060 | 3-5分钟 | 5x | 高 |
| NVIDIA RTX 4080 | 1-3分钟 | 10x | 高 |
| Apple M1 | 4-7分钟 | 3-4x | 低 |
| Apple M2 | 3-5分钟 | 4-5x | 低 |
| Apple M3 | 2-4分钟 | 5-6x | 低 |
实际性能会因具体硬件配置、系统状态、视频内容和其他因素而有所不同。
故障排除
CUDA 相关问题
-
"无法初始化 CUDA"错误:
- 确认已安装兼容的 CUDA Toolkit
- 验证显卡驱动程序是否最新
- 检查显卡是否支持所需的 CUDA 版本
-
"显存不足"错误:
- 使用较小的模型(如 small 或 base)
- 减少并行任务数
- 关闭其他使用 GPU 的应用程序
-
性能不如预期:
- 检查是否有其他程序占用 GPU 资源
- 确认已选择正确的优化版本安装包
- 更新显卡驱动到最新版本
Core ML 相关问题
-
Core ML 未自动启用:
- 确认使用的是 mac-arm64 版本的妙幕
- 检查 macOS 版本是否支持
- 重启应用程序尝试重新检测
-
"找不到 encoder.mlmodelc"错误:
- 确认已下载并正确放置对应模型的 encoder.mlmodelc 文件
- 对于非量化模型,encoder.mlmodelc 文件是必需的
-
性能不如预期:
- 检查 Mac 是否处于节能模式
- 关闭后台运行的资源密集型应用程序
- 确保 Mac 没有过热(可能导致性能降频)
硬件加速与模型选择建议
根据您的硬件配置选择合适的模型和加速方式:
高性能 NVIDIA 显卡(RTX 3000/4000系列)
- 推荐使用 large-v3 或 medium 模型
- 启用 CUDA 加速
- 可以同时处理 1-2 个任务
中端 NVIDIA 显卡(GTX 1000/1600系列,RTX 2000系列)
- 推荐使用 medium 或 small 模型
- 启用 CUDA 加速
- 建议单任务处理
Apple Silicon Mac(M1/M2/M3系列)
- 推荐使用 medium 或 small 模型
- Core ML 加速会自动启用
- M1 建议使用 small 模型,M2/M3 可尝试 medium 模型
仅有 CPU 的设备
- 推荐使用 small 或 base 模型
- 考虑使用量化模型(如 small.q8_0)减少内存占用
- 可以通过增加处理线程数提高性能
总结
硬件加速可以显著提高妙幕的处理速度,让您更快地完成字幕生成任务。根据您的设备选择合适的加速方式和模型,能够在保证字幕质量的同时,充分发挥硬件性能。对于需要处理大量视频的用户,硬件加速是不可或缺的功能。