模型配置
妙幕(SmartSub)使用 Whisper 模型进行语音识别和字幕生成。本章节将详细介绍如何下载、管理和选择适合您需求的模型。
模型管理界面
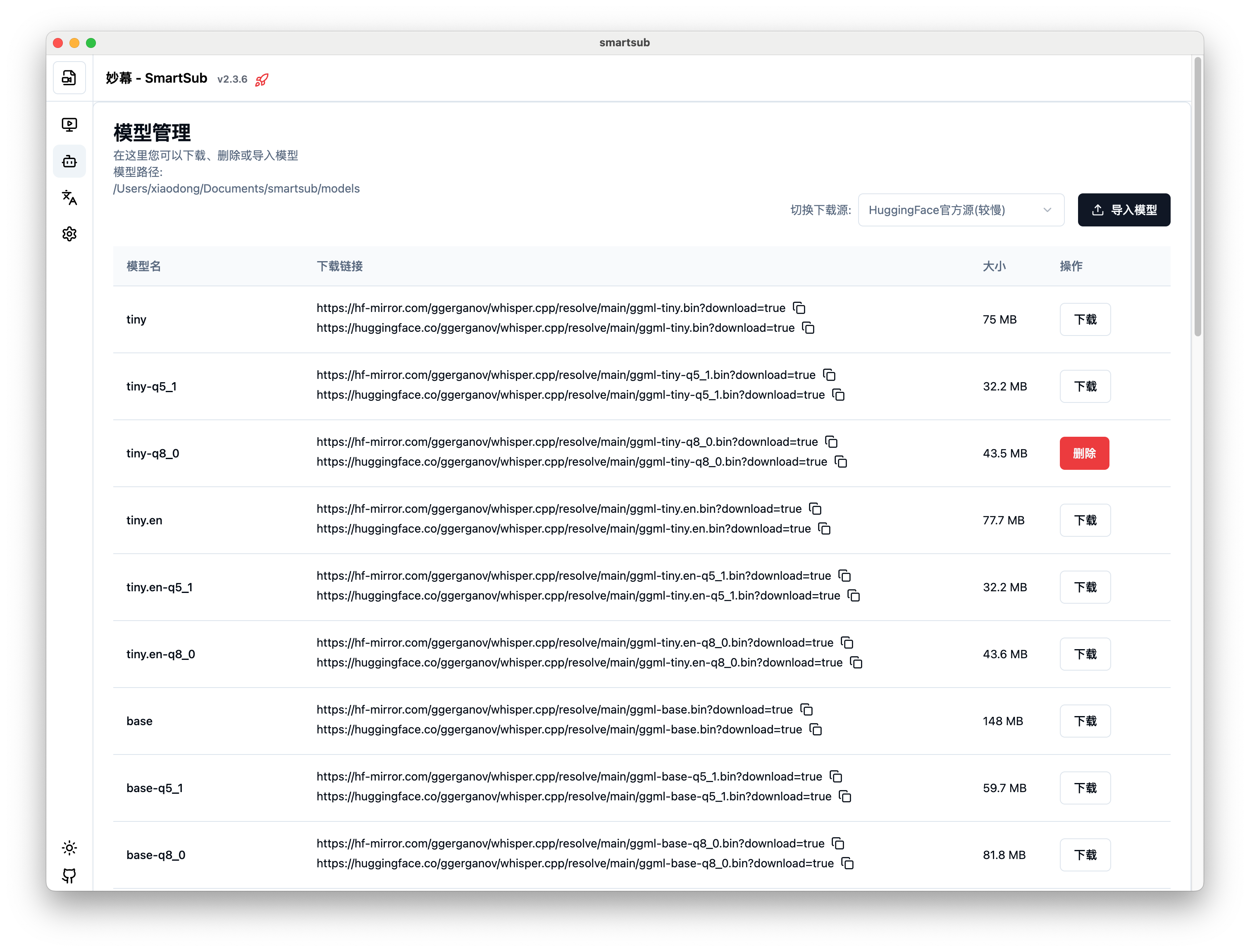
Whisper 模型简介
Whisper 是 OpenAI 开发的强大语音识别模型,能够支持多语言识别、转录和翻译。妙幕使用的是针对该模型的优化版本,使其能够在本地设备上高效运行。
可用模型一览
妙幕支持多种不同大小和精度的 Whisper 模型,根据您的需求和硬件条件选择合适的模型:
| 模型名称 | 大小 | 准确性 | 处理速度 | 内存占用 | 适用场景 |
|---|---|---|---|---|---|
| tiny | ~75MB | 低 | 非常快 | 很低 | 简单内容,资源受限环境 |
| tiny.en | ~75MB | 低(英语优化) | 非常快 | 很低 | 英语内容,资源受限环境 |
| base | ~142MB | 中低 | 快 | 低 | 普通内容,入门使用 |
| base.en | ~142MB | 中低(英语优化) | 快 | 低 | 英语内容,入门使用 |
| small | ~466MB | 中 | 中等 | 中等 | 大多数普通场景 |
| small.en | ~466MB | 中(英语优化) | 中等 | 中等 | 英语内容,平衡选择 |
| medium | ~1.5GB | 高 | 较慢 | 较高 | 需要高精度场景 |
| medium.en | ~1.5GB | 高(英语优化) | 较慢 | 较高 | 英语内容,高精度需求 |
| large-v1 | ~2.9GB | 很高 | 慢 | 高 | 专业内容,最高质量需求 |
| large-v2 | ~2.9GB | 很高 | 慢 | 高 | 专业内容,最高质量需求 |
| large-v3 | ~2.9GB | 很高 | 慢 | 高 | 最新版本,精度最高 |
量化模型
为了减小模型体积并提高加载速度,妙幕也支持量化版本的模型,例如:
- small.q5_0 - small 模型的 5 位量化版本
- medium.q8_0 - medium 模型的 8 位量化版本
量化模型在精度上有轻微损失,但文件体积更小,加载速度更快。
如何下载模型
妙幕提供了两种下载模型的方式:
1. 通过软件界面下载
- 在左侧导航菜单中点击"模型管理"
- 在"可用模型"列表中找到您想要下载的模型
- 点击对应模型旁边的"下载"按钮
- 等待下载完成(下载进度会显示在界面上)
2. 手动下载并导入
如果您遇到网络问题或需要加速下载,可以手动下载模型并导入:
-
从以下链接下载模型文件:
-
对于苹果芯片(Apple Silicon)的 Mac 用户,您还需要下载对应模型的 encoder.mlmodelc 文件(q5 或 q8 系列模型除外)
-
下载完成后,使用以下任一方法导入:
- 方法1:点击"导入模型"按钮,选择下载的模型文件
- 方法2:直接将模型文件复制到妙幕的模型目录
模型目录位置
妙幕的模型文件默认存储在以下位置:
- Windows:
%APPDATA%\Smart Sub\models\ - macOS:
~/Library/Application Support/Smart Sub/models/ - Linux:
~/.config/Smart Sub/models/
你也可以在设置里面修改模型的保存位置,把它修改为你磁盘上面的其它目录。但请 不要使用中文路径
模型选择指南
根据场景选择
- 入门体验:如果您是初次使用或只想快速尝试,使用
tiny或base模型 - 日常使用:对于大多数普通视频,
small模型通常能提供很好的平衡 - 高质量需求:对于专业内容、口音较重或背景噪音大的情况,使用
medium或large模型 - 低性能设备:在老旧设备上,使用
tiny或base模型,可能还需要选择量化版本
根据语言选择
- 英语内容:对于纯英语内容,选择带
.en后缀的模型(如small.en)可获得更好结果 - 多语言内容:对于包含多种语言或非英语内容,使用不带后缀的模型(如
small) - 中文内容:中文识别通常在
medium或以上模型效果较好
根据硬件选择
- 标准电脑:
small或small.q5_0模型适合大多数现代电脑 - 高性能设备:有较好 CPU/GPU 的设备可以尝试
medium或large模型 - 低性能设备:老旧设备或低配置设备建议使用
tiny或base模型的量化版本
硬件加速与模型
妙幕支持使用硬件加速提高处理速度:
NVIDIA CUDA 加速
如果您的设备有 NVIDIA 显卡并安装了相应的 CUDA Toolkit:
- 在"设置"中选择"系统设置"选项卡
- 将"音频设备"设置为"CUDA"
- 较大模型(如
medium或large)会特别受益于 CUDA 加速
Apple Core ML 加速
对于搭载 Apple Silicon 芯片的 Mac 设备:
- 确保使用的是 mac-arm64 版本的妙幕
- 软件会自动启用 Core ML 加速
- 对于非量化模型(非 q5 或 q8 系列),需要同时下载对应的 encoder.mlmodelc 文件
模型管理技巧
管理多个模型
- 安装多个模型:可以根据不同场景安装多个模型
- 移除不需要的模型:通过点击模型旁的"删除"按钮释放磁盘空间
- 更新模型:当有新版本可用时,可以删除旧版本并下载新版本
故障排除
-
下载失败:
- 检查网络连接
- 尝试使用手动下载方式
- 使用代理或VPN(如果您所在地区访问国际网络受限)
-
模型加载失败:
- 确认模型文件完整
- 检查是否有足够的系统内存
- 对于 Apple Silicon 设备,确认是否下载了对应的 encoder.mlmodelc 文件
-
处理速度过慢:
- 尝试使用较小的模型
- 启用硬件加速(如适用)
- 关闭其他占用系统资源的应用